ChatGPT jest już właściwie w powszechnym użyciu, ale wciąż niewiele osób zdaje sobie sprawę z tego, w jaki sposób działa. Generowanie odpowiedzi na wprowadzany prompt z perspektywy użytkownika jest procesem zajmującym nawet kilkadziesiąt milisekund. Jednak głębiej, na płaszczyźnie, której nie widzimy, nieustannie zachodzą zaawansowane procesy, które mają na celu zrozumienie promptu i znalezienie właściwej odpowiedzi. W tym artykule analizujemy, jak działają duże modele językowe, w jaki sposób zbudowany jest ChatGPT, jaka jest rola architektury Transformer i które pole całego procesu najbardziej wymaga zmian.

Rozwój sztucznej inteligencji i uczenia maszynowego na przykładzie ChatGPT
ChatGPT, stworzony przez Open AI, jest jednym z najgłośniejszych osiągnięć w dziedzinie A.I. i pierwszym tak szybko rozpowszechnionym rozwiązaniem. To zaawansowany, duży model językowy (LLM), który wykorzystuje uczenie maszynowe do generowania odpowiedzi na wprowadzane prompty na podstawie dostarczonego tekstu wejściowego. Pod koniec 2023 roku ChatGPT obsługiwał ponad 10 milionów zapytań indywidualnych dziennie. Tygodniowo z technologii korzysta 100 milionów użytkowników. Zanim zagłębimy się w działanie samego ChatGPT, warto zrozumieć szeroki kontekst, w jakim operuje ta technologia.
Definicji sztucznej inteligencji jest wiele, a te, które dotyczą wyłonienia faktycznego potencjału decyzyjnego zdolnego do podejmowania decyzji w sposób podobny, jak człowiek, bazują na testach Turinga i ich wariantach. Nowe rozwiązania określane są jako sztuczna inteligencja, choć nie ma na to powszechnej zgody. NIe zmienia to jednak faktu, że są to systemy zdolne zarówno do podejmowania decyzji własnych w pewnym określonym polu, jak i wykonywania zadań z dużą swobodą operacyjną.
Największy wpływ na rozwój A.I. mają postępy w dziedzinie uczenia maszynowego (machine learning) i głębokiego uczenia (deep learning). Technologia ta de facto zrewolucjonizowała każdy sektor technologiczny, otwierając nowe możliwości i wyzwania. To właśnie zdolności do samodzielnego uczenia się sprawiają, że narzędzia te podlegają własnym procesom bieżącej modernizacji. Wymagają modernizacji, ale nie jest konieczny stały nadzór.
Dzięki wykorzystaniu sieci neuronowej do przetwarzania danych wejściowych i uczenia maszynowego do wzbogacania baz wykorzystywanych do generowania odpowiedzi ChatGPT uznawany jest za najbardziej elastyczny i kompleksowy chatbot. Podczas etapu generowania odpowiedzi na prompt model wykorzystuje wiedzę zgromadzoną w trakcie treningu oraz konwersacji, dzięki czemu lepiej rozumie konteksty logiczne. Wpływa też na to zastosowanie mechanizmów uwagi, które sprawiają, że ChatGPT orientuje się, które elementy promptu są najistotniejsze dla użytkownika i które szczególnie należy wykorzystać na etapie generowania odpowiedzi.
Jak działa ChatGPT? Prompt – odpowiedź – interakcja
Możliwość udzielania płynnych odpowiedzi, które czasem brzmią nawet do złudzenia podobnie względem stylu komunikacji człowieka, wynika z technik przetwarzania języka naturalnego (Natural language processing; NLP). Komunikat użytkownika przetwarzany jest jako prompt, który stanowi kontekst dla generowanej odpowiedzi. Model ChatGPT, oparty na architekturze Transformer i wstępnie wytrenowany na ogromnym zbiorze danych tekstowych, analizuje ten prompt i na jego podstawie generuje odpowiedź. Proces ten opiera się na zrozumieniu kontekstu dialogu, analizie składniowej zdań, a także semantyce słów dzięki wykorzystaniu rozszerzeń znaczeniowych. Następnie wygenerowana odpowiedź jest prezentowana użytkownikowi, tworząc w ten sposób interaktywny dialog.
Główna oś działania inteligentnego czata polega na relacji prompt – odpowiedź – interakcja. W dalszej części artykułu wyjaśnimy, jakie dokładnie procesy kryją się za każdym z tych członów (bo tych naprawdę nie brakuje!). Już na tym etapie jednak wyróżnia się trzeci człon: interakcja. Ciągłe zbieranie doświadczenia na podstawie już odbytych konwersacji pozwala na sprawniejsze generowanie odpowiedzi, które pasują do intencji użytkownika. Kontekst interakcji odgrywa istotną rolę w generowaniu odpowiedzi, umożliwiając modelowi analizę wcześniejszych wypowiedzi użytkownika i zachowanie spójności w dialogu. Dzięki temu ChatGPT może generować bardziej naturalne, gramatycznie poprawne i adekwatne odpowiedzi, co przyczynia się do lepszej jakości interakcji z użytkownikiem.
5 etapów generowania treści – od promptu do cyklu dialogu
Proces konwersacji z ChatGPT i innymi alternatywnymi modułami komunikacyjnymi bazującymi na LLM wymaga nieustannego wzbogacania bazy wiedzy, z której korzystają algorytmy. Aby konwersacja była użyteczna, proces obejmuje zarówno działania początkowe, związane z odszyfrowywaniem treści użytkownika tak, by stanowiła informację zrozumiałą dla algorytmów, jak i wykorzystanie już udzielonych odpowiedzi.
Główne 5 etapów generowania treści:
- Przetwarzanie wejścia – wprowadzony przez użytkownika prompt zaczyna być przetwarzany i przekształcany do takiej formy, która będzie zrozumiała dla modelu językowego. Na tym etapie następuje kodyfikacja i procesy NLP.
- Generowanie odpowiedzi – na podstawie przetworzonego wejścia model generuje odpowiedź, korzystając z informacji zawartych w treningowym zbiorze danych i kontekstu rozmowy.
- Ocena odpowiedzi – jeszcze zanim użytkownik zobaczy wiadomość algorytm przejdzie przez etap oceny odpowiedzi. Wewnętrzne kryteria odpowiadają za weryfikację spójności tekstu, adekwatności do tematu itd., szczegółowych wytycznych użytkownika itd.
- Publikacja odpowiedzi – finalnie odpowiedź jest zaprezentowana użytkownikowi.
- Cykl dialogu – algorytm zapamiętuje wcześniejsze odpowiedzi, które wpływają na powstawanie kolejnych. Generowanie kolejnej odpowiedzi bierze pod uwagę ostatnią także wiadomość.

Przetwarzanie wejściowego promptu (NLP)
Najwięcej procesów dzieje się na pierwszym etapie komunikacji, kiedy prompt zostaje zatwierdzony przez użytkownika. Wówczas algorytm staje przed pierwszym poważnym problemem: co oznacza przesłany zbiór znaków? Do zrozumienia przekazu konieczne jest najpierw przetwarzanie języka naturalnego na zespół znaczeń zrozumiałych dla algorytmów.
Najważniejsze elementy procesu NLP (Natural Language Processing) obejmują:
- Tokenizacja – pierwszy etap dekodowania polegający na segmentowaniu promptu. Komunikat jest dzielony na mniejsze jednostki treści, które nazywamy tokenami. Tokenizacja umożliwia zrozumienie ChatGPT struktury zdania i rodzaju treści przesłanych przez użytkownika.
- Analiza składniowa – istotnym etapem NLP jest analizowanie promptu na poziomie języka. Podzielone części promptu, tokeny, są badane w poszukiwaniu cech charakterystycznych pod względem hierarchii, struktury gramatycznej itd. Informacje te wywołują później poszczególne komendy przy tworzeniu tekstu, dzięki czemu możliwe jest uzyskanie sytuacji, w której ChatGPT może upodabniać styl swojej wypowiedzi do komunikatów użytkownika.
- Dekodowanie i osadzanie – wstępnie przetworzone tokeny muszą zostać zakodowane w taki sposób, aby odpowiadały kategoriom poznawczym algorytmów. Na tym etapie zachodzi osadzanie (ang. embedding) tokenów w postaci wektorów liczbowych z zakodowaną semantyką. Prowadzi to do formy zrozumiałej dla algorytmu, która następnie jest dopasowywany do kontekstów i grup znaczeniowych zgodnie z przyjętymi mapami wiedzy. ChatGPT nie jest strukturą jednorodną, a bardziej zespołem naczyń powiązanych. Przetworzony i osadzony prompt użytkownika trafia do grupy odpowiedzialnej za konkretne konteksty. Etap dekodowania może składać się z wielu subetapów w zależności od struktury promptu, klasyfikacji zadania i kontekstów.
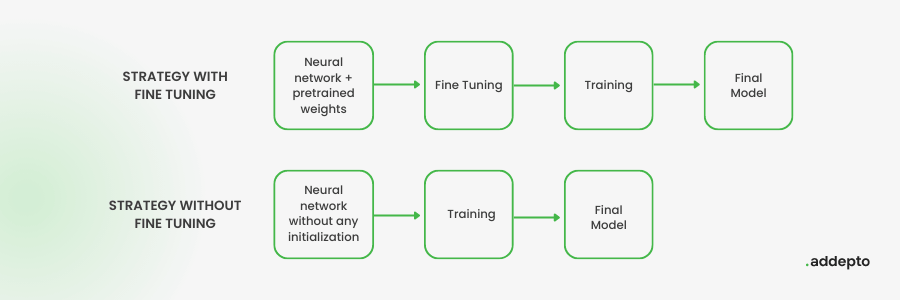
- Fine tuning – to nowa część zarówno budowy LLM, jak i kolejny element procesu przetwarzania, w ramach którego przetworzony prompt staje się elementem dla kolejnego treningu modelu, ale jednocześnie przed generowaniem odpowiedzi dostosowuje się parametry modelu w celu najlepszej odpowiedzi na pytanie. Proces fine tuning jest szczególnie istotny w sytuacji, gdy prompt zostaje zaklasyfikowany do specyficznej grupy znaczeń, np. zapytań związanych z tematyką specjalistyczną. Model automatycznie podlega własnej modyfikacji, aby lepiej odzwierciedlać cechy i wzorce obecne w nowych danych treningowych.
- Analiza źródłowa – po tokenizacji, analizie, osadzeniu i dostosowaniu do kontekstów model przetwarza dane źródłowe w celu znalezienia informacji najlepiej odpowiadających na dany prompt. Jakość rezultatów zależy od efektywności technik uczenia maszynowego i deep learning modelu, efektywności procesu fine tuning, a także rodzaju i liczby baz, na których szkolono dany model.
- Generowanie odpowiedzi – etap przetwarzania promptu NLP kończy się generowaniem odpowiedzi, która musi być spójna semantycznie i gramatycznie z pytaniem lub wypowiedzią użytkownika. Dzięki temu ChatGPT może produkować bardziej naturalne i adekwatne odpowiedzi.
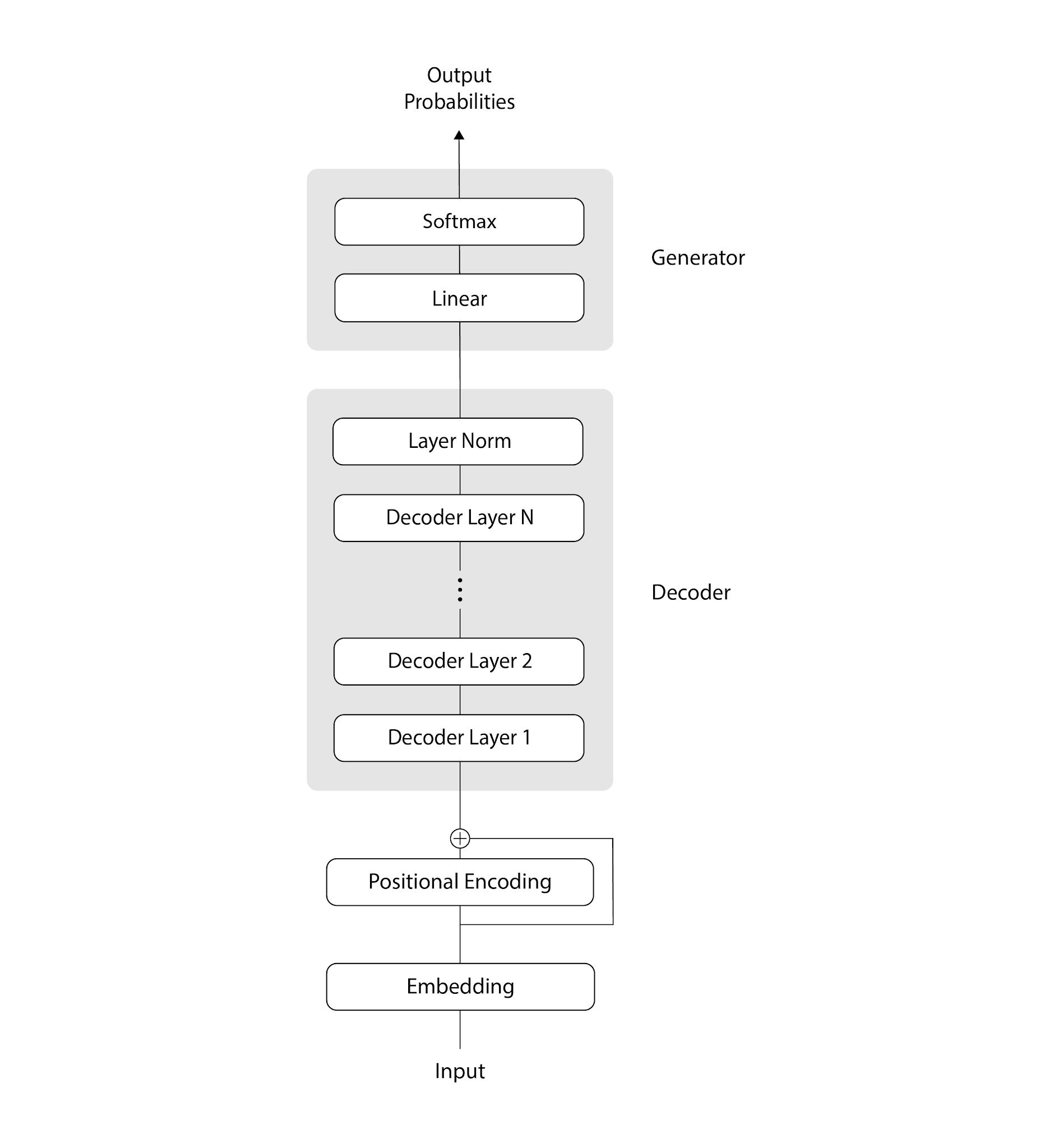
Architektura Transformer – klucz do zrozumienia efektywności ChatGPT?
ChatGPT wykorzystuje architekturę Transformer (stąd nazwa: Generative Pre-Trained Transformer; GPT), nad którą developerzy Open AI pracują co najmniej od 2017 roku. Pierwsza wzmianka o zastosowaniu i charakterystyce tej architektury pojawia się na łamach artykułu pt. Attention is all you need opublikowanego w 2017 roku przez Arxiv Cornell University. Swoją drogą, wśród autorów opracowania wymieniony jest także Polak, absolwent matematyki Uniwersytetu Wrocławskiego, Łukasz Kaiser, za którego sprawą można mówić o tym, że GPT w jakimś stopniu również ma polskie korzenie.
Transformer odpowiada za przetwarzanie sekwencji danych, takich jak zdania lub fragmenty tekstu, przeprowadzanie wyżej opisanych procesów związanych z NLP, a także generowanie odpowiedzi. Składa się z dwóch głównych warstw: Multi-Head Attention i Feedforward Neural Networks. Zanim jednak do tego przejdziemy, odpowiedzmy na pytanie, jaką rolę pełni architektura Transformer w ChatGPT i za co tak naprawdę odpowiada?
Architektura Transformer odpowiada za całokształt przetwarzania danych sekwencyjnych. Głównym zadaniem jest nie tylko analiza promptu, ale przede wszystkim badanie relacji zachodzących pomiędzy poszczególnymi elementami. Relacje te zachodzą zarówno na płaszczyźnie składniowej, ale także semantycznej i kontekstualnej.
Self-Attention Mechanism
Rdzeniem architektury Transformer, na której opiera się ChatGPT, jest mechanizm samodzielnego zwracania uwagi (Self-Attention Mechanism). Pozwala to modelowi oceniać wagę poszczególnych elementów promptu na różnych płaszczyznach i analizować relacje między nimi Mechanizm oblicza ważoną sumę wartości na podstawie podobieństwa zachodzącego między wektorami zapytania, wektorami klucza i wektorami wartości.
Pod względem proceduralnym mechanizm atencji odpowiada za utrzymywanie komunikacji pomiędzy przetwarzanymi tokenami. Mechanizm uwagi należy do warstwy dekodera, który wchodzi w skład wcześniej przytoczonych procesów działających w obrębie przetwarzania promptu. Należy pamiętać, że wszystkie procesy i subprocesy są ze sobą powiązane rezydualnie i przeskokowe. Pierwsze dostarczają alternatywną ścieżkę dla przepływu danych w sieci neuronowej, co pozwala na pominięcie niektórych warstw i lepsze parametry treningowe. Drugi wariant połączeń ma charakter nie-hierarchiczny i występuje pomiędzy różnymi poziomami systemu w celu weryfikacji przepływu danych i nie tylko. Podwaliny działania takiego framework zostały zaprezentowane już w 2015 roku w artykule pt. Deep Residual Learning for Image Recognition.
Multi-Attention Mechanism
Aby uchwycić różne rodzaje relacji między słowami, architektura musi być zaprojektowana tak, aby używać wielu różnych zestawów mechanizmów self-attention. Wyniki różnych takich mechanizmów są ze sobą łączone i zawsze zachodzą w relacji względem innych. Te kategorie, które są w nich wspólne, nazywamy blokami Multi-Attention Mechanisms bądź Multi-headed Self-Attention.
Bloki te odpowiadają za przetwarzanie różnych wariantów uwagi równolegle. Obejmują także przetwarzanie informacji przed i po procesie. W procesie biorą udział 3 tensory: zapytanie (query), klucz (key) i wartość (value). Mechanizm umożliwia modelowi analizowanie zależności między różnymi tokenami znajdującymi się w danej sekwencji poprzez obliczanie uwagi dla każdej pary tokenów. W przypadku GPT Multi-headed Attention przetwarza sekwencję tokenów wejściowych dla każdej pary tokenów w różnych blokach (“głowach”).
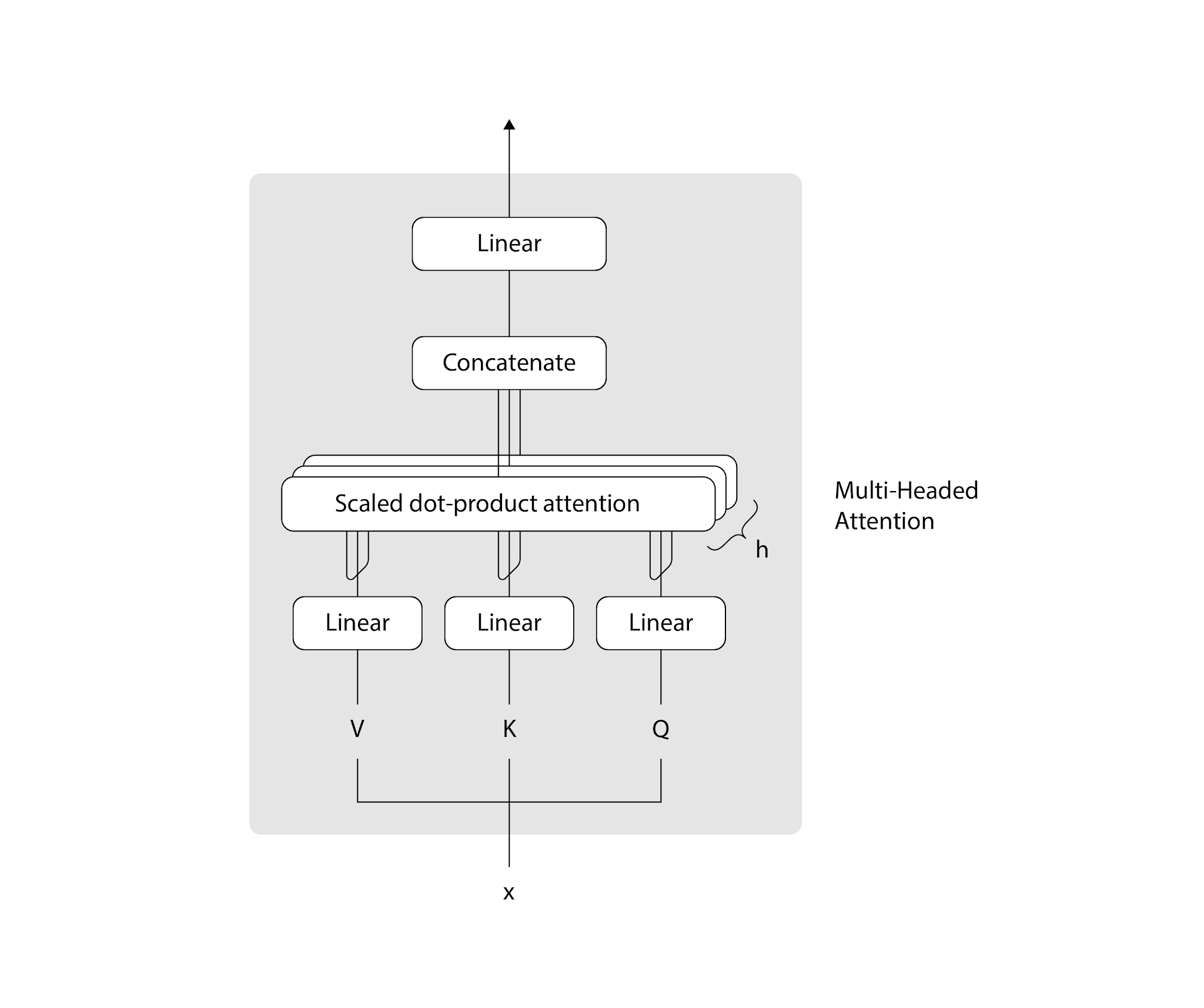
Zaletą jest to, że każdy z tych bloków może skupić się na badaniu różnych, odmiennych aspektów relacji zachodzących między tokenami. Przekłada się to na możliwości detekcji różnych wzorców i zależności w obrębie promptu i jego kontekstu. Przykładowo, jeden blok mechanizmu może być wrażliwy na semantyczne podobieństwo między tokenami, podczas gdy inny może być zorientowany na analizę właściwości i zależności syntaktycznych promptu.
Multilayer perceptron (MLP)
Po przetworzeniu tokenów przez mechanizmy uwagi rezultaty przekazywane są do zmultiplikowanych warstw MLP (Multilayer perceptron). Na tym etapie przetworzone uprzednio dane z promptu są filtrowane liniowo w celu dalszej identyfikacji zależności występujących w danych liczbowych. ChatGPT posiada na tej płaszczyźnie funkcje nieliniowe i liniowe, takie jak Rectified Linear Unit.
MLP jest rodzajem sieci neuronowej typu feedforward. Konstrukcja takich sieci polega na tym, że jednostki przekazywane są tylko w jednym kierunku, od węzłów wejścia do węzłów wyjścia, bez pętli i cykli. Sieć neuronowa pozwala jednak nie tylko odróżniać cechy niecharakterystyczne i badać zależności danych wejściowych. W module MLP zachodzą też procesy związane z automatyczną nauką, która zachodzi w perceptronie. Po przetworzeniu danych następuje zmiana wag poszczególnych połączeń, które jest weryfikowana z ostatecznym rezultatem, co stanowi przykład samodzielnego uczenia się typu nadzorowanego.
Szkolenie ChatGPT
Architektura Transformer we wszystkich wersjach ChatGPT (GPT-3, GPT-3.5, GPT-4) umożliwia płynną naukę i zdolność wyciągania wniosków z konwersacji przeprowadzanych z użytkownikiem. Początkowo model przeszedł proces zwanym nadzorowanym dostrojeniem, w trakcie którego trenerzy z Open AI pełnili rolę zarówno użytkowników, jak i botów A.I. Umożliwiło to dalsze prace związane z sekwencjonowaniem dialogów i sposobem naśladowania komunikacji. Model został następnie ulepszony poprzez implementację mechanizmu nagrody. Dobre odpowiedzi były zaznaczane przez testerów jako poprawne, niewłaściwe jako błędne. Dane wykorzystane do treningu miały obejmować 570 GB danych ilościowych i jakościowych, w tym publikacje naukowe, artykuły webowe, książki, encyklopedie i inne źródła.



Architektura Transformer ChatGPT
Seria GPT praktycznie w każdej iteracji stanowi przykład najbardziej zaawansowanych obecnie modeli językowych LLM. Paradoksalnie użyteczność ChatGPT może być kwestionowana ze względu na brak dostępu do najnowszych treści i informacji. Pomimo tego w codziennej pracy to właśnie ten model językowy okazuje się najskuteczniejszy i najprostszy w korzystaniu. Wynika to przede wszystkim ze specyfiki architektury Transformer, której poszczególne elementy – mechanizmy uwagi, bloki uwagi, MLP – gwarantują najlepsze możliwości analizy promptu.
Komunikaty użytkownika analizowane są wielokrotnie na różnych płaszczyznach, a sama kolejka procesów jest niezwykle długa i skomplikowana. Najbardziej rewolucyjna technologia w obrębie ChatGPT to Self-Attention Mechanisms i Multi-headed Self-Attention. Wielokrotne dekodowanie, próbkowanie i sekwencjonowanie promptu w obrębie różnych tensorów umożliwia wychwytywanie znaczeń, których inne modele językowe nie dostrzegają.
Sztuczna inteligencja w postaci ChatGPT, czy po prostu GPT (Generative Pre-Trained Transformer), wcale nie jest sztuczną inteligencją. Nie ma własnej woli, ani intuicji, nie jest w stanie przejść testów Turinga, ale świetnie “udaje”, dzięki mechanizmom detekcji intencji użytkownika, że faktycznie rozumie, co ma się na myśli. ChatGPT od Open AI jest niezwykle zaawansowanym zespołem autoweryfikujących procesów diagnostyki semantycznej i składniowej, zawierającej bardzo rozbudowane płaszczyzny tokenizacji i dekodowania. Będziemy uważnie śledzić dalszy rozwój modelu.

