Wiele mówi się o dużych modelach językowych, ale nie tylko one mogą być rewolucyjne dla branży IT i innych sektorów. Zespół Google Research właśnie zaprezentował silny argument potwierdzający tę tezę. ScreenAI to nowoczesny model języka wizualnego, który może zmienić sposób analizy treści wizualnych, generowania obiektów i nawigowania interfejsami użytkowników. Przyglądamy się najnowszemu wynalazkowi Google i sprawdzamy, w czym tkwi jego przełomowość!

ScreenAI – model języka wizualnego od Google
Na blogu Google Research znajdziemy wiele ciekawych projektów, za które odpowiada gigant z Kaliforni. Niedawno ukazała się premierowa prezentacja najnowszego osiągnięcia: Screen AI. Na czym polega?
ScreenAI to model języka wizualnego do zrozumienia UI i infografik. Ulepsza architekturę PaLI poprzez model łatania z pix2struct. ScreenAI klasyfikowany jest jako duży model językowy, przy czym nie jest wykorzystywany do generowania treści. ScreenAI ma być wykorzystywane do zarządzania interfejsami, analizą danych wizualnych, generowania infografik i projektów UI. Model ma być w stanie rozumieć, wnioskować oraz interaktywnie pracować z różnymi interfejsami na zasadzie projektowania, programowania i wykorzystywania języka wizualnego (ikony, układy, zależności).

Początki ScreenAI. Na drodze do lepszego rozumienia obrazów
Fundamentalne prace nad narzędziem do zarządzania i analizy UI wykorzystującego modele językowe zostały położone już kilka lat temu. W maju 2023 r. na łamach Arxiv Cornell University zostaje opublikowana praca PaLi-X: On Scaling up a Multilingual Vision and Language Model. To wielojęzyczny model wizualny i językowy, który ma osiągać nowe poziomy wydajności w szerokim zakresie zróżnicowanych zadań opartych na analizie obrazów, układów graficznych, a także treści.
W artykule czytamy, że “architektura PaLi-X umożliwia lepsze rozumienie dokumentów opartych na obrazie i nauce w małych zbiorach danych”, a także detekcję obiektów, obrazów i układów. Test empiryczny na podstawie kilkudziesięciu benchmarków, którego wyniki prezentowane są w powyższym artykule, faktycznie udowadnia wyższy stopień efektywności wykonywania zadań w porównaniu do alternatywnych systemów.
Zespół Google Research przyznaje, że baza kodowa ScreenAI zajmuje zaledwie 5B. To wystarcza, aby uzyskiwać najwyższej jakości rezultaty w zakresie przetwarzania obrazów, generowania infografik czy modyfikowania zróżnicowanych układów UX. ScreenAI wykonuje zadania w obrębie WebSRC, MoTIF, Chart QA i Infographic VQA.
ScreenAI – architektura i analiza danych wizualnych
ScreenAI ulepsza architekturę PaLI dzięki elastycznej strategii łatania z pix2struct. Architektura oparta na PaLi składa się z wielomodalnego bloku enkodera (ang. multimodal encoder block) i autoregresywnego dekodera (ang. autoregressive decoder). Enkoder architektury PaLI wykorzystuje transformer wizji (ViT), który tworzy osadzenie obrazu, a także koder wielomodalny, który przyjmuje konkatenację osadzeń obrazu i tekstu w formie wejścia.

Taka struktura sprzyja rozwiązywaniu skomplikowanych zadań wymagających analizy relacji wizualnych. Mówiąc kolokwialnie; obiekty, ich układ, charakterystyka – to w gruncie rzeczy zawsze jakaś relacja, którą można poznawać poprzez język. ScreenAI dzięki zmodyfikowanej architekturze PaLi z pix2struct jest w stanie elastycznie rozwiązywać zadania wymagające zrozumienia danego układu. Zrozumienie zaś to nic innego jak zdekodowanie informacji, zakodowanie do odpowiedniego języka, przetworzenie i przesłanie dalej. Rezultatem pracy ScreenAI jest rozwiązywanie zadań opartych na analizie wizualnej, które można następnie przekształcić w problemy tekst + obraz do tekstu.
Dekodowanie, kodowanie, klasyfikowanie
Model wizualno-językowy ScreenAI jest szkolony na dwóch etapach: wstępnego szkolenia i dostrajania. Najpierw stosuje się uczenie “samonadzorowane” (ang. self-supervised learning) w celu automatycznego generowania etykiet danych, które są następnie używane do szkolenia ViT i modelu językowego. ViT jest zamrożony podczas etapu dostrojenia, kiedy większość danych podlega etykietyzacji i pracy manualnej testerów Google.
Do wstępnego szkolenia wykorzystywany jest zbiór danych, który tworzony jest poprzez kompilację obszernych kolekcji zrzutów ekranów z różnych urządzeń. Google używa setek tysięcy obrazów ze stron internetowych, z urządzeń stacjonarnych i mobilnych. Następnym krokiem w szkoleniu jest zastosowanie anotatora w postaci układu opartego na modelu DETR (Detection Transformer). Odpowiada on za identyfikację i oznaczanie szerokiego zakresu elementów interfejsu użytkownika (np. obrazów, piktogramów, przycisków, treści tekstowej itd.). Na tym etapie identyfikowane są także relacje przestrzenne, które zachodzą pomiędzy różnymi obiektami. Piktogramy przechodzą dalszą analizę za pomocą klasyfikatora ikon zdolnego do rozróżniania 77 różnych typów ikon, co z pewnością będzie jeszcze rozszerzane w przyszłości.
Etap klasyfikacji jest niezwykle istotny w całym procesie i to właśnie od niego zależy efektywności wykonywanych zadań. Google tłumaczy, że stosuje model generowania podpisów obrazów PaLI, aby wygenerować opisowe podpisy, które dostarczają kontekstowych informacji. Inne treści są analizowane przy użyciu optycznego silnika rozpoznawania znaków (OCR). Wszystkie te informacje w postaci adnotacji – z OCR, z klasyfikatorów ikon, enkodera językowego i DETR – są ostatecznie łączone ze sobą, aby uzyskać szczegółowy opis dla każdego obrazu.
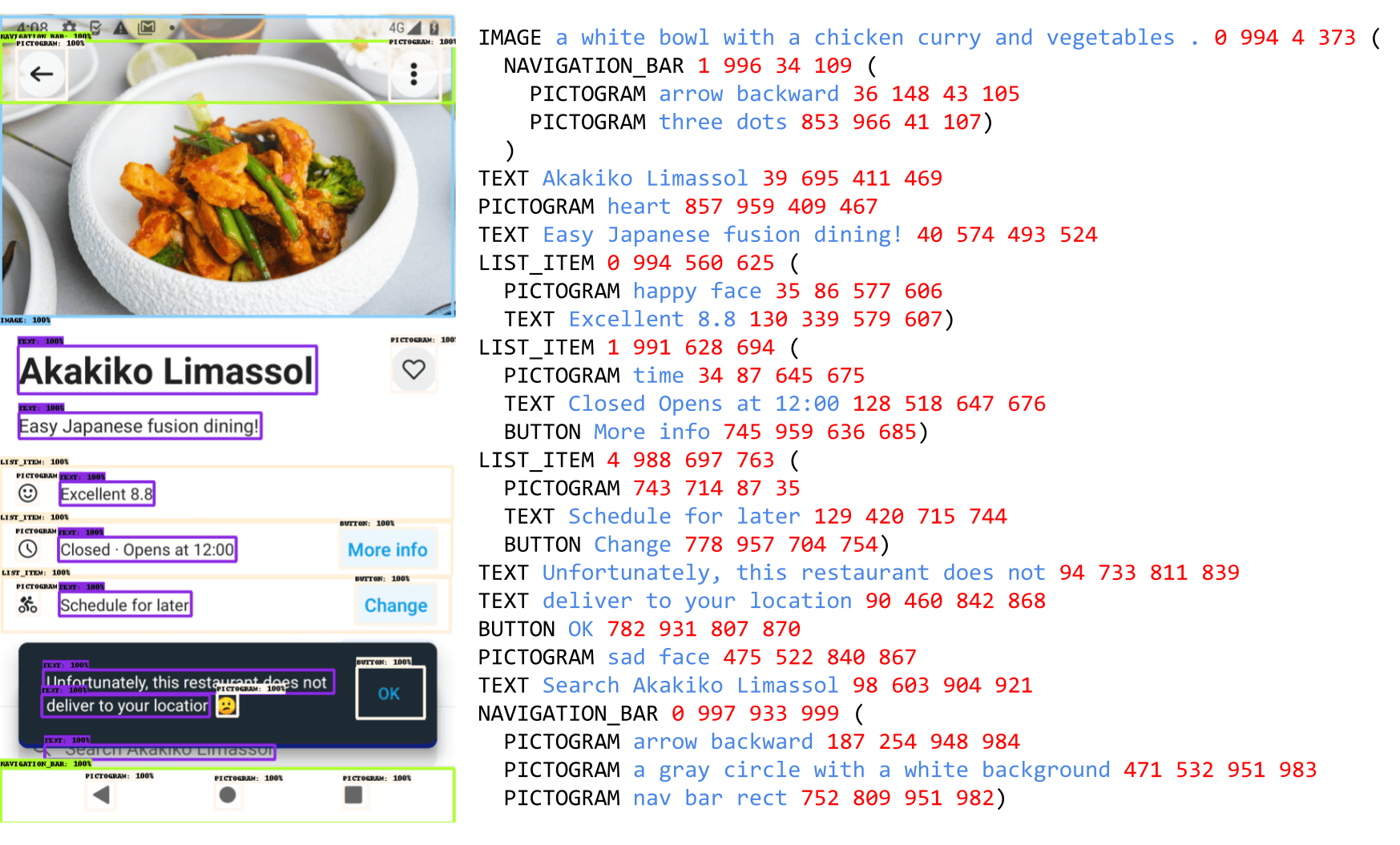
Generowanie danych
Poprzez wykorzystanie PaLM 2 w procesie generowania danych przed szkoleniem system jest w stanie tworzyć zróżnicowane zestawy danych. Proces rozpoczyna się od generacji adnotacji ekranu, a następnie tworzenia pytań na ich podstawie przy udziale dużego modelu językowego. Realizacja tego procesu wymaga precyzyjnego formułowania pytań oraz uczenia iteracyjnego, znanego doskonale m.in. z architektury Transformer – głównego systemu ChatGPT.
Obecnie ostateczna ocena jakości generowanych danych przeprowadzana jest poprzez ręczną weryfikację. Jednak już na obecnym poziomie automatyzacji poszczególnych działań ScreenAI wykorzystując kombinacje zdolności językowych LLM oraz strukturyzowanego schematu danych potrafi analizować i wykonywać różne zaawansowane działania. Model odpowiada na pytania, wykonuje zadania związane z nawigacją na ekranie, analizuje obiekty i ich relacje.

Rezultaty efektywności i nowe benchmarki
Kluczowym etapem w trakcie szkolenia modelu ScreenAI jest dostrajanie. Odbywa się ono przy użyciu zestawów danych zawierających pytania i odpowiedzi, podsumowania oraz nawigację oraz różnorodne zadania związane z interfejsami użytkownika. W przypadku pytań i odpowiedzi Google stosuje benchmarki w zakresie multimodalności i analizy treści oraz dokumentów, takie jak m.in. ChartQA, DocVQA, DocVQA, InfographicVQA, OCR VQA, Web SRC oraz ScreenQA. W nawigacji używane są różne zestawy danych, takie jak m.in. Referring Expressions, MoTIF, Mug oraz Android in the Wild. Ponadto Google analizuje też elementy interfejsu użytkownika przy użyciu danych Screen2Words oraz Widget Captioning do opisywania konkretnych elementów.
Nowością jest zastosowanie trzech nowych benchmarków, które umożliwiają szerszą ocenę narzędzia. Zaliczamy do nich:
- Adnotacje ekranu – własny benchmark Google, który ma pozwalać na ocenę adnotacji układu modelu oraz jego zdolności do rozumienia obiektów przestrzennych,
- ScreenQA Short – wariant ScreenQA, w którym odpowiedzi na pytania zostały skrócone, zawierając tylko istotne informacje i lepiej dopasowując się do innych zadań typu QA,
- Complex ScreenQA – rozszerzony zestaw ScreenQA Short, który został wzbogacony o trudniejsze pytania (m.in. dotyczące analizy takich obszarów, jak działania arytmetyczne, porównania i pytania bez możliwości odpowiedzi).
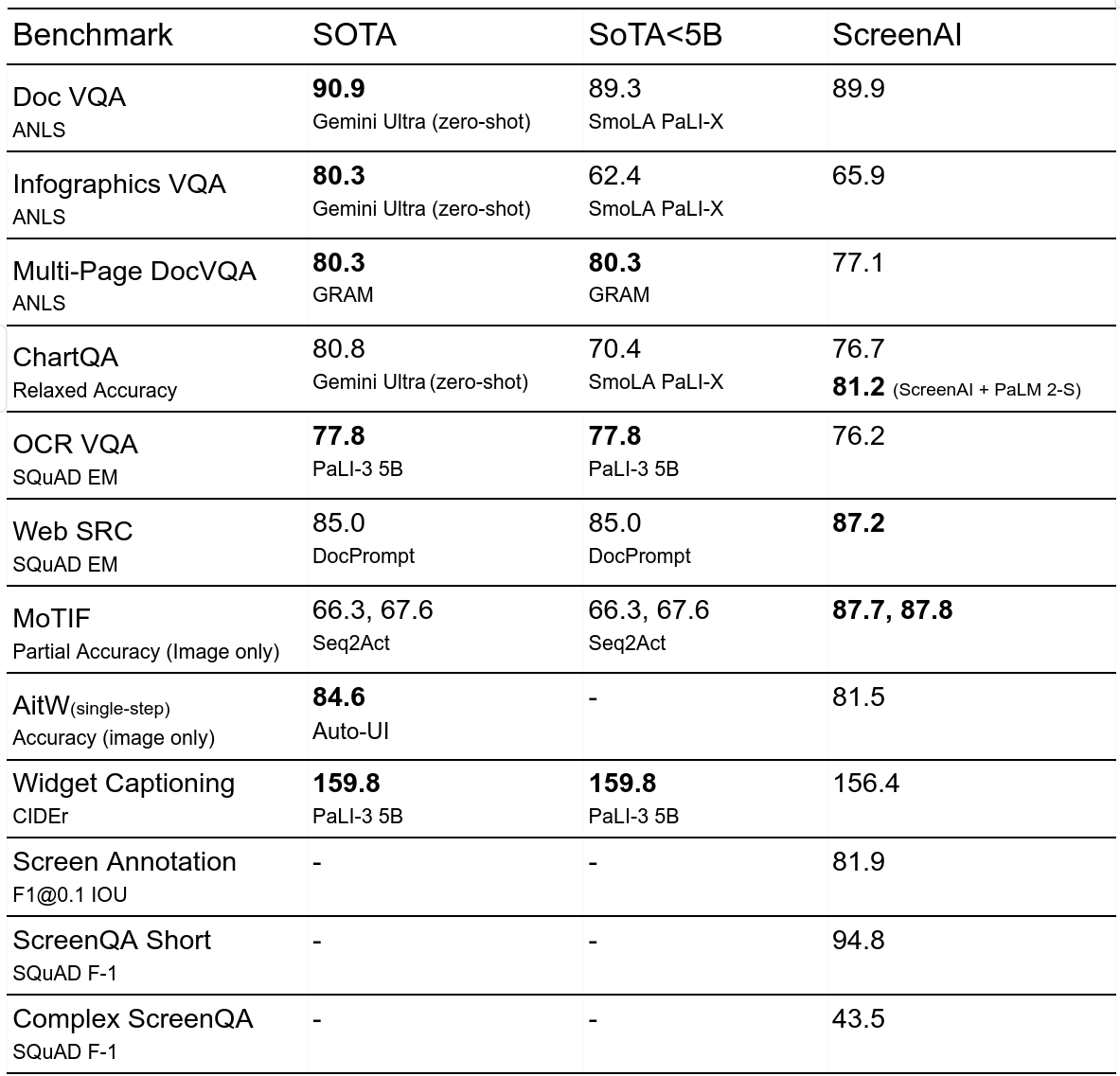
W serii benchmarków dotyczących sztucznej inteligencji ScreenAI osiągnął bardzo dobre wyniki (WebSRC, MoTIF, Chart QA i DocVQA). ScreenAI osiąga konkurencyjne wyniki w Screen2Words i OCR-VQA. Google zastrzega jednak, że „Rozwój ScreenAI wciąż jest w tyle za dużymi modelami i konieczne są dalsze prace, aby zniwelować te różnice”.
Ciekawie potraktowano również fazy testowe związane z odpowiadaniem na sztucznie generowane pytania użytkowników dotyczące kontekstów związanych z obrazami i obiektami. Zawierały one szczegółowe pytania wymagające umiejętności weryfikacji danych informacji z całego obszaru składającego się zarówno z samego tekstu, jak elementów graficznych. Model był też testowany w zakresie weryfikacji możliwych interakcji przez użytkownika, np. znajdowania przycisków decyzyjnych, elementów interaktywnych itd. Z sukcesem odpowiada również na pytania o podsumowanie, np. “Co zawiera zrzut ekranu – wyjaśnij w dwóch zdaniach”.


ScreenAI – nowy model języka wizualnego – podsumowanie
Model ScreenAI od Google Research nie jest może tak spektakularnym projektem, jak ChatGPT oparty na architekturze Transformer, ale stanowi kolejny przełom w dziedzinie analizy interfejsów użytkownika oraz danych wizualnych. Charakteryzuje się wysoką skutecznością w różnorodnych zadaniach polegających na analizie obrazów, relacji między obiektami przestrzennymi, elementami interaktywnymi i nie tylko. Wprowadzenie nowych benchmarków, takich jak ScreenQA Short i Complex ScreenQA, pozwala na lepszą ocenę jego zdolności. Niestety, ogólne wyniki pokazują, że projekt znajduje się jeszcze w dość wczesnej fazie, a jego skuteczność będzie musiała być istotnie zwiększona zanim Google przejdzie do fazy implementacji narzędzi.
Na pewno jednak wprowadzenie ScreenAI stanowi kolejny krok Google w zakresie rozwoju technologii AI w ogóle. Nie wiemy jeszcze, czy zaprezentowane funkcjonalności będą dostępne w formie standalone, czy zostaną zintegrowane w obrębie większego systemu, np. Gemini. Zastosowań zresztą jest bez liku. Na ScreenAI skorzystać mogą projektanci UI/UX i webdeveloperzy. Nawet w obrębie Google Tag Manager można znaleźć czynności, np. identyfikację tagów reklamowych, które byłyby lepiej wykonywane przez bądź przy użyciu Google ScreenAI. Narzędzie to ma więc niewątpliwie duży potencjał praktycznych zastosowań i na pewno będziemy przyglądać się dalszemu rozwojowi projektu.

