Zespół Google Research opublikował badania dotyczące poprawy wydajności klawiatury Google. Gboard, bo o niej mowa, to domyślny model klawiatury zaimplementowany domyślnie w smartfony Google Pixel, ale dostępny także jako aplikacja do pobrania. Jeżeli ktoś w tym momencie zastanawia się, czy w obrębie klawiatury na telefon do pisania tekstu mogą powstawać jakiekolwiek rewolucje technologiczne, odpowiadamy: zdecydowanie tak! Google nie tylko znacznie poprawia efektywność i intuicyjność pisania na telefonie, ale również proponuje ciekawe rozwiązania z zakresu A.I. oraz ochrony prywatności. Bierzemy na warsztat najnowsze wyniki badań i sprawdzamy, czy Gboard lada moment stanie się najlepszym modelem klawiatury dostępnym na rynku?

Rewolucja w pisaniu wiadomości. Nowe zmiany w Google Gboard
19 kwietnia na platformie Research Google pojawiły się wyniki badań i ostatniej implementacji najnowszych zmian w obrębie modułu klawiatury na smartfony (Improving Gboard language models via private federated analytics). Mowa oczywiście o Google Gboard – module, którego nazwa jest raczej mało popularna wśród użytkowników, za to z pewnością rozpoznawalna przez developerów aplikacji mobilnych. Gboard to domyślna klawiatura telefonów Google Pixel, ale także aplikacja dla smartfonów z różnymi OS. Zadebiutowała w 2016 roku.
W ostatniej aktualizacji zespół badawczy Google wprowadził szereg zmian związanych z poprawą wydajnością Gboard, ale także sposobem zachowania prywatności danych użytkowników. W tym celu analitycy mieli współpracować z lingwistami w celu doskonalenia słowników i korpusów. Opracowano innowacyjne techniki ochrony prywatności oparte na analizie federatywnej i różnicowej prywatności w celu wykrywania słów spoza słownika. Do tego dochodzą zmiany w zakresie dużych modeli językowych, które klasyfikują się do grupy A.I. Poniżej sprawdzamy krok po kroku, czym jest i jak działa najnowsza wersja klawiatury Gboard.
Ewolucja Gboard: od zwykłej klawiatury do inkluzywnego modelu A.I.
Gboard to opracowana przez Google wirtualna klawiatura w formie aplikacji na smartfony, tablety i inne urządzenia mobilne. Premiera Gboard miała miejsce w maju 2016 roku. Aplikacja dostępna jest dla urządzeń z systemem iOS i Android (premiera: grudzień 2016 r.). Gboard spełnia wszystkie funkcje standardowych klawiatur urządzeń przenośnych, ale jednocześnie znacznie wykracza poza ich funkcjonalność. Aplikacja oferuje funkcje wyszukiwania Google i generowanie odpowiedzi predykatywnych, częściowo automatycznych. Pierwsze wersje aplikacji umożliwiały także przeglądanie wyników z sieci bezpośrednio przez Gboard – funkcja ta została jednak wycofana w kwietniu 2000 r. Oprócz tego Gboard zapewnia udostępniania treści GIF-ów i emoji, silnik predykcyjny do wprowadzania tekstu sugerujący każde kolejne słowo w zależności od kontekstu i dotychczasowej wypowiedzi, a także szerokie wsparcie dla tłumaczeń i opcji związanych z wielojęzycznością.
Na początku klawiatura od Google obsługiwała ponad 100 języków, a od 2019 r. 916 języków. Obecnie liczba ta dochodzi do tysiąca. Od strony wizualno-użytkowej Gboard prezentuje się bardzo solidnie, schludnie, a jednocześnie efektownie. Ma szereg pomniejszych funkcji, takich jak sugestie GIF-ów, opcje ciemnego motywu kolorów i własnych obrazów tła klawiatury, obsługę głosowego wprowadzania treści wiadomości, możliwość manualnego rysowania emoji i znaków specjalnych (podobnie, jak np. w Google Docs).
Jednym z najistotniejszych features Gboard jest silnik predykcyjny Google, który był chwalony m.in. przez The Wall Street Journal. Podstawą jego cechą jest zdolność uczenia maszynowego sprawiająca, że korzystanie z Gboard staje się coraz łatwiejsze i bardziej intuicyjne z biegiem czasu. “Automat” znacznie lepiej niż jego główni rywale radzi sobie z odczytywaniem intencji użytkownika, analizując szerszą gamę kontekstów dzięki wbudowanym dużym modelom językowym.
Klawiatura Google z dużymi modelami językowymi (LLM)
Gboard wykorzystuje duże modele językowe (LLM) w zakresie przetwarzania promptu (wiadomości) użytkownika oraz wiadomości przez niego otrzymywanych. Dzięki temu pisanie przy pomocy Gboard jest bardziej intuicyjne, a silnik jest w stanie zaskakująco dobrze przewidywać kolejne słowa. Z dużych modeli językowych korzystają też inne funkcje, takie jak korekta automatyczna, inteligentne uzupełnianie, przeciąganie do pisania itp.
Autorzy najnowszego raportu badawczego nt. Google Gboard twierdzą, że modele językowe Gboard są zaprojektowane do pracy z predefiniowaną listą często używanych słów, nazywaną ogólnie jako słownictwo (ang. vocabulary). Słowa, które nie są częścią słownictwa, nazywane są słowami spoza słownika (ang. out-of-vocabulary; OOV). Słowa OOV mogą występować w Gboard z kilku powodów i ze względu na różne zastosowania pełnią inne funkcje. Przede wszystkim sprzężone z modelami językowymi silniki algorytmiczne mają za zadanie identyfikować trendy językowe, nietypowe wielkości liter i pisownię ze względu na preferencje użytkowników.
Odkrywanie słów OOV jest zadaniem wymagającym ze względu na wrażliwy charakter informacji, które użytkownicy wpisują na swojej klawiaturze. Rodzi to szereg problemów związanych z ochroną danych – często nawet danych wrażliwych. Najnowsza aktualizacja Gboard umożliwia udostępnienie użytkownikom informacji o wykorzystaniu danych i kontroli konfiguracji oraz wprowadza zaawansowane wykorzystanie modelu uczenia federatywnego do szkolenia Gboard. Obydwie zmiany mają znacznie poprawiać bezpieczeństwo i wydajność aplikacji. Na czym dokładnie polegają?
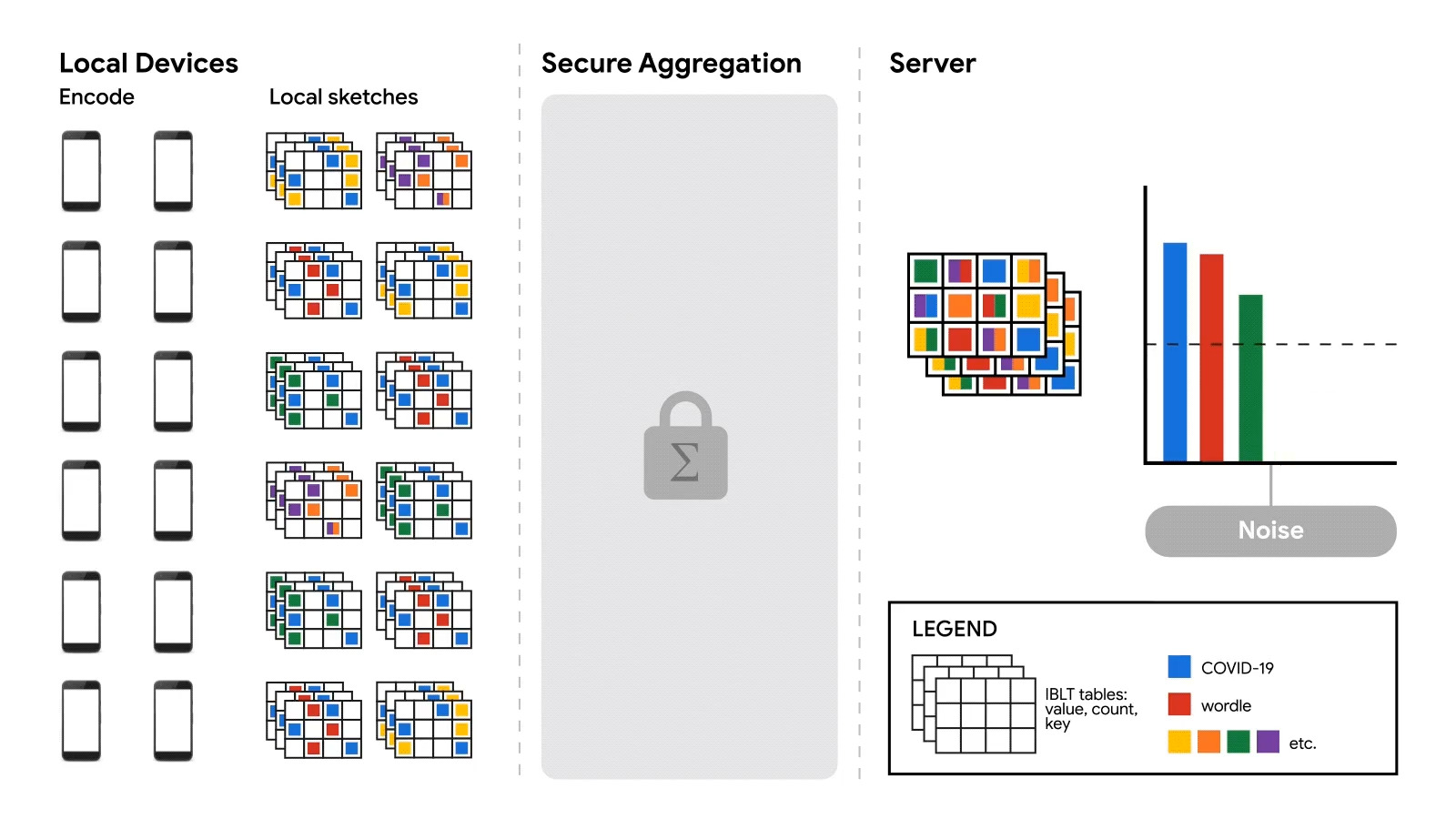
Wykorzystanie analizy federacyjnej
Zespół Google Research stwierdza, że odkrywanie nowych słów, rozumienie tekstu i przesyłanie propozycji w Gboard będzie od teraz znacznie dokładniejsze. Wszystko za sprawą rewolucji w obszarze przetwarzania treści poprzez duże modele językowe. Jednocześnie najnowsza odsłona Gboard, dostępna już do pobrania, jest pierwszą wersją, w której zastosowano analizy federatywne i zaufane środowiska wykonawcze (TEE) w celu ochrony prywatności danych.
Funkcjonowanie mechanizmów, które chronią wrażliwe informacje użytkowników zarówno podczas zbierania danych, jak i ich przetwarzania, zapewniane jest przez wykorzystanie przez Google Research korzyści wynikających z analizy federacyjnej. Analiza federacyjna to metoda minimalizacja danych do obliczeń statystycznych na rozproszonych zbiorach danych bez udostępniania wrażliwych danych. Bezpieczeństwo możliwe jest dzięki rozdzieleniu procesu na dwa składowe etapy:
- Przetwarzanie danych – przetwarzanie umożliwiające dokonywanie obliczeń na zbiorach rozproszonych zachodzi jeszcze na lokalnych urządzeniach lub serwerach.
- Agregacja wyników – rezultaty są agregowane bez ujawniania samych danych z wykorzystaniem metod bezpiecznej agregacji i prywatności różnicowej. Sam proces agregacji zachodzi bez ujawniania szczegółowych danych z etapu pierwszego.
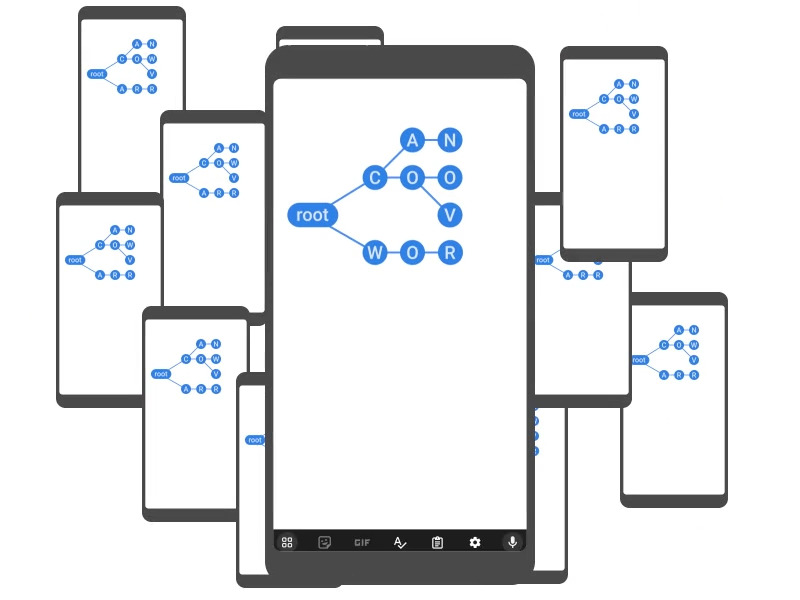
Model SecAggIBLT – liniowe struktury danych i tabele mieszające Blooma
SecAggIBLT – autorska architektura przetwarzania informacji Google Research – bazuje na tabelach mieszających Blooma (IBLT) i SecAgg. Każdy z tych dwóch komponentów jest równie istotny. Wyjaśnijmy pokrótce, na czym polegają.
SecAgg to bezpieczna agregacja, czyli opisana powyżej technika wykorzystująca analizę federacyjną do przetwarzania danych, umożliwiająca agregację wyników z zachowaniem prywatności indywidualnych danych i ich źródeł. Z kolei tabele Blooma pewnego rodzaju struktury danych używane do przechowywania i wyszukiwania elementów w dużych zbiorach danych. W modelu Google SecAggIBLT odpowiadają one przede wszystkim za weryfikację, czy nowy element należy do zbioru, czy nie.
Zastosowanie tabel Blooma nie wymaga implementacji mechanizmów odpowiadających za przechowywanie całych danych, ani ich kluczy. Wynika to z tego, że tabele Blooma wykorzystują tablice bitowe i własne funkcje haszujące. Każdy bit reprezentuje pewną informację lub wartość logiczną. Funkcje haszujące IBLT przekształcają dane wejściowe (np. klucze) na indeksy, które są osadzone w tablicy bitowej. Dzięki temu tabele Blooma są w stanie efektywnie weryfikować przynależność danych elementów do zbioru danych, jednocześnie zapewniając bezpieczeństwo i poufność informacji, niskie zużycie pamięci i krótki czas potrzebny na wykonanie operacji.

Zabezpieczenie danych użytkownika – mechanizm centralnej różnicowej
Zespół Google Research twierdzi, że takie podejście zapewnia anonimowość dla nowych słów wstawianych przez użytkowników, dbając o ich prywatność. Co więcej, prywatność jest zapewniana także przez dodatkowe mechanizmy ochrony danych, w tym mechanizm centralnej różnicowej (central differential privacy). Technika ta zapewnia prywatność danych w obrębie wszystkich wykonywanych procesów. Polega na wprowadzeniu “sztucznego szumu” do wyników analizy w taki sposób, aby indywidualne wkłady danych nie mogły być odtworzone. W praktyce oznacza to dodawanie losowych zakłóceń do wyników analizy, co utrudnia identyfikację konkretnych uczestników lub wartości w zbiorze danych. Więcej technicznych informacji na temat sposobu działania technologii centralnej różnicowej można znaleźć m.in. na Tensorflow.
Nowe fenomeny językowe wyprowadzane z danych użytkowników mogą pochodzić z różnych źródeł i zawierać różne znaczenia. Dane te mogą też zawierać elementy wrażliwe, np. numery kart kredytowych, adresy, imiona i nazwiska. Dlatego Google Research podkreśla, że bezpieczeństwo przetwarzania ich jest priorytetem wszystkich aktualnych prac. Połączenie SecAggIBLT – bazującego na analizie federacyjnej i tabelach Blooma – z mechanizmem centralnej różnicowej ma umożliwiać odkrywanie unikalnych słów przez system (we współpracy z LLM), a jednocześnie chronić przed przeglądaniem odkrytych słów przez serwer i jakiekolwiek inne podmioty.
Co ciekawe, prywatność zapewniana jest także poprzez ograniczenie wpływu zmian przez poszczególnych użytkowników. Innymi słowy, liczba nowych słów identyfikowanych przez system i pochodzących od jednego użytkownika jest ograniczona do 1 słowa dziennie w okresie 60 dni. W przypadku, gdy system “wychwyci” więcej nowych słów od użytkownika do zaadaptowania, ograniczy bardziej to źródło tak, aby nie dochodziło do sytuacji, w której słowa z jednego źródła są nadreprezentowane w ogólnym rozrachunku. Według Google mechanizm ten gwarantuje optymalny kompromis pomiędzy użytecznością a prywatnością.


Google Gboard – rewolucja w pisaniu wiadomości. Podsumowanie
O Google Gboard mówi się niewiele, co jest zrozumiałe. Klawiatura smartfona to nie jest coś, czym zwykliśmy się emocjonować. Od strony technologicznej jednak rozwiązania implementowane w obrębie Gboard stanowią doskonałe pole do nauki sposobu radzenia sobie z wrażliwymi danymi rozproszonymi, które trzeba zebrać, przetworzyć, a najlepiej jeszcze – uczyć się na ich podstawie i wyprowadzać wnioski.
Najnowsze zmiany technologiczne w obrębie Gboard pokazują, że zespół Google Research osiągnął już wiele. Priorytetem jest zwiększenie prywatności użytkowników, szczególnie w kontekście potencjalnie wrażliwych wprowadzanych danych. Google stosuje przełomowy model SecAggIBLT, który bazuje na analizie federacyjnej i tabelach Blooma do przetwarzania, dekodowania i zabezpieczania danych. Wprowadzony mechanizm centralnej różnicowej umożliwia zwrotne “zaszumianie” wyników (obscuring data) w obrębie serwera, jak i do urządzeń wejściowych. Metoda ta umożliwia dodawanie losowych zakłóceń do rezultatów analizy, uniemożliwiając tym samym identyfikację konkretnych danych i ich autorów w finalnym zbiorze. Mechanizm ograniczania wkładu każdego użytkownika w celu uniknięcia nadreprezentatywności dodatkowo chroni system nie tylko pod względem bezpieczeństwa danych użytkowników, ale także w kontekście naturalizacji procesu dodawania nowych słów i znaczeń do LLM.
Za prezentowanymi zmianami kryje się coś jeszcze. Trzeba bowiem pamiętać o tym, że mechanizmy, które przedstawiliśmy w kontekście Gboard, tak naprawdę są szeroko związane z sektorem A.I. Jednak o ile w obrębie czatów konwersatoryjnych Microsoft i Open AI mogą mieć przewagę, o tyle na płaszczyźnie apek wykonawczych do smartfonów Google konkuruje de facto tylko z Apple. I kto wie, czy w tej niszy nie wygra?

