Noindex i nofollow to oznaczenia wykorzystywane w obrębie strony internetowej. Jak wskazuje pierwszy człon obu wyrażeń – „no”, czyli „nie” – są to polecenia kierowane do robotów wyszukiwarek, by nie podejmowały działania. Warto jednak podkreślić, że atrybut nofollow i noindex nie są sobie równe i dotyczą innych akcji. Ponadto zakaz śledzenia może występować także jako pojedyncze linki nofollow. Skomplikowane? Już tłumaczymy; koniecznie przeczytaj!

Czym jest atrybut nofollow?
Popularniejszy, jako że wykorzystywany w kilku odmiennych tagach, jest atrybut nofollow. Pojawia się w obrębie całej podstrony bądź występuje jako pojedyncze linki nofollow. Stanowi informację dla robotów wyszukiwarek, np. Google, by nie śledziły umieszczonego w treści odnośnika i nie przekazywały zewnętrznej witrynie mocy strony, na której się znajduje.

Linki nofollow a meta nofollow
Atrybut nofollow może mieć charakter zarówno pojedynczy, jak i całościowy. W pierwszym przypadku chodzi o pojedyncze linki nofollow, np. w artykule opublikowanym na blogu. Przydaje się chociażby w sytuacji, gdy autor nie ma zaufania do strony, do której odnośnik umieścił w tekście. Może to być także strona firmy, z którą współpracuje komercyjnie, a za umieszczenie linku otrzymał wynagrodzenie. Wówczas, zgodnie z polityką Google, odnośnik powinien mieć oznaczenie nofollow lub nowszą wersję: rel=”sponsored”.
Zdarza się jednak, że z jakichś powodów właściciel strony internetowej chce zamienić wszystkie linki dofollow widoczne na danej podstronie w nofollow. Dodawanie atrybutu do każdego odnośnika zajęłoby dużo czasu, zwłaszcza gdy na podstronie występuje ich sporo. Wówczas przydaje się komenda <meta name=”robots” content=”nofollow”>, którą umieszcza się w sekcji <head> danej podstrony. Za jej sprawą wszystkie odnośniki zmieniają charakter. Roboty Google i innych wyszukiwarek odczytują je jako nofollow.
Co daje atrybut nofollow?
Atrybut nofollow to oznaczenie informujące roboty – a w rzeczywistości jedynie sugerujące im – że nie powinny zwracać uwagi na zawartość strony internetowej, do której prowadzi odnośnik. Ponadto nie powinny przekazywać jej mocy witryny wyjściowej (tzw. link juice). „No follow” to w dosłownym tłumaczeniu „nie śledzić”, zatem funkcja atrybutu zawiera się w jego nazwie.
Jako oznaczenie przy pojedynczych linkach atrybut nofollow wygląda następująco:
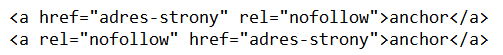
Forma jest dowolna, ponieważ nie ma znaczenia, czy atrybut pojawi się tuż za otwarciem tagu <a, czy dopiero za adresem strony internetowej.
Z kolei w kodzie HTML tagu meta robots dyrektywa przybiera następującą postać:
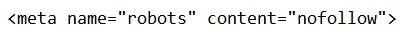
Kiedy stosować atrybut nofollow?
Zgodnie z wytycznymi Google linki o charakterze nofollow wykorzystuje się w sytuacjach takich jak:
- brak zaufania wobec podlinkowej strony internetowej (ma to miejsce np. na blogach w sekcji komentarzy oraz na forach, kiedy autor nie ma kontroli nad publikowaną treścią; tutaj można wykorzystać również rel=”ugc”),
- współpraca komercyjna, w której link został opłacony (na potrzeby artykułów i innych treści sponsorowanych powstał alternatywny wobec nofollow atrybut rel=”sponsored”),
- nagromadzenie linków, przez które roboty Google musiałyby poświęcić bardzo dużo czasu, by prześledzić wszystkie (w tym wypadku – w określonych sytuacjach – wygodnym rozwiązaniem będzie użycie rozwiązanie nofollow meta, czyli zablokowanie śledzenia wszystkich odnośników przy pomocy jednej komendy w sekcji <head> danej podstrony).
Ale to nie koniec! W obszernym poradniku-regulaminie SEO pracownicy Google wspominają również o „innych sytuacjach”, w których właściciel danej strony internetowej może chcieć skorzystać z atrybutu nofollow. Nie wyszczególniają ich, pozostawiając decyzję odbiorcom.
Dodatkowe powody do zastosowania atrybutu nofollow
Niektórych stron internetowych nie warto udostępniać robotom wyszukiwarki do śledzenia. Może się zdarzyć, że w tekście wykorzystasz stronę niskiej jakości jako przykład tego, jak nie należy czegoś robić – wobec niej doskonały będzie atrybut nofollow (choć możesz też pozostawić link nieklikalnym; chętni skopiują i wkleją go do paska przeglądarki sami).
Odnośniki nofollow możesz zastosować również w odniesieniu do stron firm, z którymi współpracujesz (producentów, dostawców, sklepów internetowych, a nawet Twojej agencji SEO). Dalej nie ma powodu, dla którego roboty miałyby odwiedzać podstrony, na których treść jest skąpa bądź nie ma jej wcale. W sklepie internetowym są to chociażby podstrony do rejestracji, logowania, finalizowania zakupu. Atrybut nofollow sprawdzi się do oznaczenia landing pages oraz podstron zawierających głównie elementy Java czy Flash. Warto także zablokować śledzenie treści zduplikowanych, takich jak regulaminy, polityki prywatności i cookies, których nie pisze się samodzielnie, lecz kopiuje z innych stron.
Czym jest tag noindex?
Tak jak nie wszystkie linki są warte śledzenia, tak nie wszystkie podstrony są warte indeksowania. Tutaj pojawia się pole do popisu dla tagu noindex, który w tłumaczeniu na język polski oznacza dosłownie „nie indeksować”.
W przeciwieństwie do atrybutu nofollow tag noindex dotyczy nie linków, lecz podstrony (a czasem nawet całej strony, np. landing page). Służy informowaniu, by roboty wyszukiwarek – Google bądź wszystkich – nie uwzględniały danej podstrony w wynikach wyszukiwania. A jeżeli już uwzględniły, to powinny cofnąć akcję i usunąć ją z wyników wyszukiwania.

Co daje umieszczenie tagu noindex w sekcji <head>?
Dzięki dodaniu tagu noindex do kodu <head></head> danej podstrony nie pojawia się ona w wynikach wyszukiwania. To z kolei sprawia, że właściciel strony przejmuje kontrolę nad ścieżką, jaką użytkownik musi podążyć, by znaleźć się na danej podstronie. Przykładowo wyświetlanie koszyka zakupowego w wynikach wyszukiwania mijałoby się z celem. Po co użytkownikowi taka podstrona, skoro nawet nie odwiedził sklepu i nie włożył niczego do koszyka?
Inny przykład korzyści znacznika noindex to zapobiegnięcie kanibalizacji słów kluczowych. Wyobraź sobie, że pracujesz nad wypozycjonowaniem kategorii „buty zimowe” w sklepie internetowym. Roboty Google są jednak uparte i w odpowiedzi na frazę „męskie buty zimowe” wolą promować w wyszukiwarce podstronę z artykułem, który napisałeś na temat męskich butów na zimę parę lat wcześniej. W efekcie podstrona o niższej wartości pod względem konwersji zakupowej wyświetla się wyżej. Jeżeli zablokujesz ją w indeksie, będziesz mógł pracować nad właściwą.
Kiedy korzystać z tagu robots noindex?
Regułę <meta name=”robots” content=”noindex”> warto umieścić w obrębie podstrony, by nie pojawiła się w wynikach wyszukiwania, w następujących przypadkach:
- cel danej strony jest inny niż generowanie ruchu z wyników wyszukiwania (przykład: landing page),
- podstrony o treści różnej dla konkretnych użytkowników (np. będące częścią kampanii badającej preferencje odbiorców za pomocą testów A/B),
- aby wyświetlić podstronę, użytkownik powinien wcześniej wykonać konkretną akcję (dodać zakupy do koszyka, wpisać dane do formularza rejestracyjnego, pobrać plik itd.),
- podstrony z wynikami wyszukiwania, filtrowania opcji i sortowania produktów (zwłaszcza w sklepach internetowych),
- podstrony o niskiej jakości pod względem SEO (chociażby mające zduplikowane treści: regulaminy, polityki prywatności),
- podstrony niezawierające treści bądź mające jej mało (wykorzystujące animacje Flash itp., okna logowania i rejestracji),
- podstrony „marnujące” tzw. crawl budget (zabierające część z liczby podstron, które roboty mogą zaindeksować podczas wizyty w witrynie).
Noindex meta – wszystkie roboty wyszukiwarek bądź Google
Istnieje wiele wyszukiwarek internetowych, a każda z nich posługuje się swoimi robotami. Warto jednak wiedzieć, że podczas gdy główna komenda blokady indeksowania wpływa na wszystkie, istnieje formułka blokująca tylko roboty najpopularniejszej wyszukiwarki – Google. Oto różnice:

Ponadto istnieje możliwość zablokowania indeksowania nie przez wszystkie, lecz konkretne roboty Google. Przykładowo można zaniechać indeksowania obrazów (name=”googlebot-image”) czy wideo (name=”googlebot-video”). Pełną listę nazw i funkcji znajdziesz w przeglądzie Google.
Blokowanie indeksowania w pliku robots.txt
Tag noindex na pojedynczej podstronie możesz zastąpić blokadą indeksowania – a właściwie badania strony przez crawler – umieszczoną w pliku robots.txt. Żeby przekonać się, czy już masz ów plik, czy wymaga stworzenia, wpisz w okno przeglądarki:

Aby uzyskać dostęp do pliku robots.txt, wyświetl pliki umieszczone na serwerze FTP (skorzystaj np. z programu FileZilla). Odnajdź dokument robots.txt i dodaj odpowiedni wiersz:

Powyższe działanie zablokuje crawlerowi możliwość skanowania podstrony O nas. Z kolei gdybyśmy dodali wiersz: Disallow: /blog/, ukrylibyśmy w wynikach wyszukiwania – choć jedynie warunkowo – nie tylko główną podstronę bloga (tę, na której widać tytuły wszystkich artykułów), ale również każdy artykuł. Ochrona przed crawlerem objęłaby zatem wszystkie podstrony zaczynające się od adresu URL: https://funkymedia.pl/baza-wiedzy.
Uwaga! Ten sposób nie daje gwarancji efektu. Jeżeli chcesz mieć pewność, że podstrony nie pojawią się w indeksie wyszukiwarki, użyj dyrektywy noindex. Więcej o tym zagadnieniu przeczytasz we wprowadzeniu Google.
Jak ukryć podstrony bądź strony już zaindeksowane?
Opublikowałeś witrynę lub podstronę bez dodania formułki noindex i zorientowałeś się dopiero w momencie, w którym już została zaindeksowana? Nie przejmuj się! Nie musisz usuwać strony i tworzyć jej od nowa. Wystarczy, że teraz dodasz znacznik noindex w <head>. Kiedy Google bądź inny podmiot ponownie przeskanuje zawartość witryny, usunie wskazane podstrony z wyszukiwarki.
Możesz również wysłać wniosek o ukrycie podstrony w wyszukiwarce poprzez narzędzie Google Search Console. Należy jednak wiedzieć, że w ten sposób ukryjesz URL w indeksie jedynie na pewien czas. Kiedy upłynie, podstrona znów będzie widoczna w wyszukiwarce.
Tag noindex a nofollow – różnica
Zanim przejdziemy do omawiania kombinacji dyrektyw, podsumujmy główną różnicę pomiędzy noindex a nofollow:
- noindex to informacja, by nie dochodziło do indeksowania podstrony,
- nofollow to informacja, by nie dochodziło do śledzenia odnośników i przekazywania mocy z witryny wyjściowej do docelowej.
Ponadto:
- noindex wykorzystuje się do oznaczania podstrony bądź strony,
- nofollow wykorzystuje się do oznaczania pojedynczego linku bądź wszystkich odnośników podstrony/strony.
Jeżeli chcesz użyć tych oznaczeń w obrębie witryny, powinieneś umieścić je albo w kodzie pomiędzy <head> a </head>, albo w pliku robots.txt. (Przypominamy, że drugi sposób bywa zawodny).
<meta name=”robots” content=”… i co dalej?
Podstronę lub całą stronę da się oznaczyć pojedynczą dyrektywą (noindex lub nofollow meta). Można też skorzystać z kombinacji, przede wszystkim noindex plus nofollow. Poniżej opisaliśmy, jaki skutek niosą takie połączenia oraz w jakich sytuacjach są wartościowe dla stron.
Zestawienie name robots content noindex, nofollow – czyli?
Tag noindex połączony z wartością nofollow to popularna kombinacja wykorzystywana m.in. do oznaczania podstron, które po pierwsze nie powinny pojawić się w indeksie Google, po drugie zaś zawierają linki do witryn, którym nie chcemy przekazywać mocy.
Zablokowanie widoczności w indeksie z jednoczesnym nieśledzeniem linków wygląda następująco:

Zablokowanie linków (nofollow) w połączeniu z brakiem indeksowania (noindex) sprawdza się np. przy stronach o zduplikowanej treści, a więc niskiej jakości. Nie warto indeksować witryny będącej końcowym punktem ścieżki: podziękowaniem za dokonanie zakupu, dodanie opinii czy wypełnienie formularza. Niewiele wartości dla strony mają również regulaminy, których linki prowadzą do innych regulaminów i podstron „technicznych”.
Połączenie typu noindex, follow – czyli?
Wartość follow (inaczej: dofollow) stanowi domyślne oznaczenie dla każdej witryny i jej podstron. Oznacza to, że nie musisz go uwzględniać w tagu meta robots, aby był czytelny. Ma wpływ na każdy link na stronie, który w efekcie jest śledzony i służy przekazywaniu mocy.
Kombinacja robots meta noindex + follow może wyglądać następująco:

Skutek jest taki, że strona nie wyświetla się w wyszukiwarce, jednak z każdego linku przekazywana jest wartość do witryny docelowej.
Kombinacja typu nofollow, index – czyli?
Tutaj spotykamy się z podobną sytuacją do powyższej. Tag index jest domyślnym dla strony, toteż nie trzeba specjalnie go dopisywać. Kiedy występuje, dba o to, by strona była indeksowana i pojawiała się w wynikach wyszukiwarki. Ponieważ jednak u jego boku stoi dyrektywa nofollow, z żadnego linku nie przekazuje się wartości do strony docelowej.
Połączenie indeksowania strony z blokadą śledzenia odnośników wygląda tak:

Wykorzystaj tę kombinację, np. gdy napisałeś długi artykuł bogaty linki niskiej jakości czy sponsorowane. Możesz osobno otagować każdy link za pomocą jednej z komend:
- <a href=”adres-strony” rel=”nofollow”>anchor</a>
- <a rel=”nofollow” href=”adres-strony”>anchor</a>
Szybciej Ci pójdzie ze znacznikiem meta. Pamiętaj jednak, że blokada obejmuje każdy link w obrębie danej podstrony, a więc również te w nawigacji. Jeżeli chcesz się ograniczyć do zawartości artykułu, znajdź wtyczkę zgodną z CMS-em, którego używasz.
Przykład strony tag index, dofollow – czyli?
Jak już wspomnieliśmy, domyślny stan stron internetowych to obecność znaczników index i follow. Mimo iż nie znajdziesz ich w kodzie źródłowym, Google odczytuje brak blokad jako zgodę na indeksowanie w wynikach wyszukiwarki oraz śledzenie odnośników.
Zgodnie z wytycznymi Google większość podstron witryny powinna dawać się indeksować i przekazywać moc do innych stron internetowych. Tag noindex i nofollow są zarezerwowane dla wyjątkowych sytuacji, takich jak opisane w naszych artykule.


Jak uzyskać wysoką pozycję w wynikach wyszukiwania?
Pomijając podstrony o niskiej wartości dla użytkownika, strona powinna być widoczna w wynikach wyszukiwarki. Im wyższą zajmuje pozycję, tym lepiej dla Ciebie, bo widzi ją więcej użytkowników Google (bądź innej wyszukiwarki). W efekcie zwiększa się konwersja: więcej osób pojawia się na stronie, robi zakupy bądź podejmuje inne akcje, na których Ci zależy.

Na wysoką pozycję w wynikach wyszukiwarki wpływa wiele czynników, toteż pozycjonowanie jest czynnością złożoną. Zaczyna się od audytu skutkującego optymalizacją, czyli wdrożeniem poprawek. Kolejnym etapem są działania długofalowe: dbanie o wciąż nowe teksty na stronie (np. za pomocą bloga) oraz link building. Każde z tych zadań możesz zlecić nam, co oczywiście Ci polecamy.
Zachęcamy również do przejrzenia naszego bloga. Niesie wiele wartości dla osób zainteresowanych pozycjonowaniem witryny oraz innymi działaniami z zakresu marketingu internetowego. Chcesz zmienić coś na stronie? Wdrożyć nowości? A może strona wymaga odświeżenia? Poszukaj właściwych porad wśród naszych artykułów!

